Note
Using the DLRUTDataset#
This example shall give an overview of the methods and attributes that are available in the DLRUTDataset class.
Load trajectory data#
At first, we need to load the trajectory data of the dataset.
[1]:
from tasi.dlr import DLRTrajectoryDataset
from tasi.dlr.dataset import DLRUTDatasetManager, DLRUTVersion
dataset = DLRUTDatasetManager(DLRUTVersion.latest)
dataset.load()
ds = DLRTrajectoryDataset.from_csv(dataset.trajectory()[50])
[2025-04-25 12:18:50 | dataset.py:load:130] > INFO: Checking if dataset already downloaded /tmp/DLR-Urban-Traffic-dataset_v1-2-0
[2025-04-25 12:18:50 | dataset.py:load:166] > INFO: Dataset already available at /tmp/DLR-Urban-Traffic-dataset_v1-2-0
Attributes of the dataset#
There are several attributes available to get information about a dataset. For instance, we can get the interval of a dataset via the property
[2]:
ds.interval
[2]:
Interval(2023-09-24 12:30:00.016482+00:00, 2023-09-24 12:44:59.966482+00:00, closed='right')
or all unique timestamps of it via
[3]:
ds.timestamps
[3]:
DatetimeIndex(['2023-09-24 12:30:00.016482+00:00',
'2023-09-24 12:30:00.066482+00:00',
'2023-09-24 12:30:00.116482+00:00',
'2023-09-24 12:30:00.166482+00:00',
'2023-09-24 12:30:00.216482+00:00',
'2023-09-24 12:30:00.266482+00:00',
'2023-09-24 12:30:00.316482+00:00',
'2023-09-24 12:30:00.366482+00:00',
'2023-09-24 12:30:00.416482+00:00',
'2023-09-24 12:30:00.466482+00:00',
...
'2023-09-24 12:44:59.516482+00:00',
'2023-09-24 12:44:59.566482+00:00',
'2023-09-24 12:44:59.616482+00:00',
'2023-09-24 12:44:59.666482+00:00',
'2023-09-24 12:44:59.716482+00:00',
'2023-09-24 12:44:59.766482+00:00',
'2023-09-24 12:44:59.816482+00:00',
'2023-09-24 12:44:59.866482+00:00',
'2023-09-24 12:44:59.916482+00:00',
'2023-09-24 12:44:59.966482+00:00'],
dtype='datetime64[ns, UTC]', name='timestamp', length=18000, freq=None)
or the ids of all traffic participants in the dataset.
[4]:
ds.ids
[4]:
Index([1695558514712340, 1695558558975558, 1695558561769745, 1695558563216597,
1695558565170472, 1695558571572035, 1695558572272810, 1695558573520980,
1695558576618026, 1695558579216721,
...
1695559487523035, 1695559488624461, 1695559490123751, 1695559490123748,
1695559491223905, 1695559492674737, 1695559496120575, 1695559498274800,
1695559499574101, 1695559499171792],
dtype='int64', name='id', length=750)
Filtering#
If you want to look into a short sequence of the overall dataset, you can select specific rows of the overall dataset. The tasi.DLRTrajectoryDataset provides various ways for this purpose.
Time and object#
There are two variants to filter a dataset based on the information on the dataset’s index. For instance, if you want to filter the dataset by an interval, you can utilize the tasi.DLRTrajectoryDataset.during method.
[5]:
ds.during(ds.timestamps[0], ds.timestamps[10])
[5]:
| acceleration | center | classifications | dimension | interpolated | velocity | yaw | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| easting | magnitude | northing | easting | northing | bicycle | car | motorbike | pedestrian | truck | van | height | length | width | easting | magnitude | northing | ||||
| timestamp | id | |||||||||||||||||||
| 2023-09-24 12:30:00.016482+00:00 | 1695558514712340 | 1.068 | 1.698 | 1.320 | 604774.496 | 5792796.320 | 0.008 | 0.598 | 0.388 | 0.000 | 0.006 | 0.0 | 1.445 | 2.536 | 1.177 | False | 7.140 | 8.169 | -3.970 | -29.398 |
| 1695558558975558 | 0.014 | 0.016 | -0.008 | 604740.884 | 5792779.240 | 0.000 | 0.838 | 0.163 | 0.000 | 0.000 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.021 | 0.021 | 0.000 | 7.852 | |
| 1695558561769745 | 0.008 | 0.036 | -0.035 | 604787.539 | 5792764.373 | 0.000 | 0.952 | 0.037 | 0.011 | 0.000 | 0.0 | 1.311 | 3.445 | 1.409 | False | -0.008 | 0.042 | 0.041 | 107.830 | |
| 1695558563216597 | -0.041 | 0.044 | -0.014 | 604741.853 | 5792776.267 | 0.000 | 0.954 | 0.026 | 0.000 | 0.000 | 0.0 | 1.468 | 3.323 | 1.293 | False | -0.030 | 0.044 | 0.032 | 9.183 | |
| 1695558565170472 | -0.002 | 0.004 | -0.004 | 604791.430 | 5792770.438 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 | 0.0 | 1.556 | 3.407 | 1.775 | False | -0.000 | 0.013 | 0.013 | 116.146 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-09-24 12:30:00.466482+00:00 | 1695558592618702 | -1.060 | 1.065 | -0.095 | 604725.976 | 5792780.341 | 0.000 | 0.904 | 0.095 | 0.000 | 0.001 | 0.0 | 1.496 | 3.387 | 1.496 | False | 3.969 | 4.002 | 0.516 | 7.403 |
| 1695558596566965 | 0.117 | 0.194 | -0.155 | 604744.173 | 5792789.955 | 0.163 | 0.000 | 0.000 | 0.837 | 0.000 | 0.0 | 1.624 | 1.323 | 0.787 | False | 0.441 | 1.529 | -1.464 | -73.101 | |
| 1695558596716951 | 0.054 | 0.243 | -0.237 | 604742.064 | 5792846.878 | 0.000 | 0.933 | 0.062 | 0.000 | 0.000 | 0.0 | 1.368 | 2.848 | 1.394 | False | 0.674 | 2.345 | -2.246 | -73.240 | |
| 1695558598618723 | -0.116 | 0.137 | 0.072 | 604745.924 | 5792793.615 | 1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.0 | 1.445 | 0.939 | 1.029 | False | 1.345 | 2.942 | -2.617 | -62.834 | |
| 1695558598820336 | 0.091 | 0.152 | -0.122 | 604747.604 | 5792840.329 | 0.000 | 0.922 | 0.068 | 0.000 | 0.010 | 0.0 | 1.640 | 2.950 | 1.698 | False | 3.606 | 10.793 | -10.172 | -70.505 | |
172 rows × 19 columns
that returns the rows within the given interval.
Another variant to select specific rows of the datasets is by the id of a traffic participant. This might be useful if you want to take a closer look into the behavior of specific traffic participants. For instance, to filter by the second traffic participant in the dataset, we can combine the tasi.DLRTrajectoryDataset.ids attribute with the trajectory method.
[6]:
ds.trajectory(ds.ids[1])
[6]:
| acceleration | center | classifications | dimension | interpolated | velocity | yaw | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| easting | magnitude | northing | easting | northing | bicycle | car | motorbike | pedestrian | truck | van | height | length | width | easting | magnitude | northing | ||||
| timestamp | id | |||||||||||||||||||
| 2023-09-24 12:30:00.016482+00:00 | 1695558558975558 | 0.014 | 0.016 | -0.008 | 604740.884 | 5792779.240 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.021 | 0.021 | 0.000 | 7.852 |
| 2023-09-24 12:30:00.066482+00:00 | 1695558558975558 | 0.013 | 0.015 | -0.008 | 604740.884 | 5792779.240 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.023 | 0.023 | -0.001 | 7.852 |
| 2023-09-24 12:30:00.116482+00:00 | 1695558558975558 | 0.012 | 0.014 | -0.008 | 604740.884 | 5792779.240 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.025 | 0.025 | -0.001 | 7.852 |
| 2023-09-24 12:30:00.166482+00:00 | 1695558558975558 | 0.011 | 0.014 | -0.007 | 604740.884 | 5792779.240 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.028 | 0.028 | -0.002 | 7.852 |
| 2023-09-24 12:30:00.216482+00:00 | 1695558558975558 | 0.010 | 0.013 | -0.007 | 604740.885 | 5792779.240 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.030 | 0.030 | -0.002 | 7.852 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-09-24 12:30:34.216482+00:00 | 1695558558975558 | -0.242 | 0.304 | -0.183 | 604783.725 | 5792742.854 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 3.161 | 10.290 | -9.792 | -72.008 |
| 2023-09-24 12:30:34.266482+00:00 | 1695558558975558 | -0.242 | 0.304 | -0.183 | 604783.882 | 5792742.364 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 3.153 | 10.293 | -9.798 | -72.049 |
| 2023-09-24 12:30:34.316482+00:00 | 1695558558975558 | -0.242 | 0.304 | -0.183 | 604784.038 | 5792741.873 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 3.146 | 10.296 | -9.803 | -72.084 |
| 2023-09-24 12:30:34.366482+00:00 | 1695558558975558 | -0.242 | 0.304 | -0.183 | 604784.194 | 5792741.382 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 3.140 | 10.298 | -9.808 | -72.114 |
| 2023-09-24 12:30:34.416482+00:00 | 1695558558975558 | -0.242 | 0.304 | -0.183 | 604784.349 | 5792740.890 | 0.0 | 0.838 | 0.163 | 0.0 | 0.0 | 0.0 | 1.261 | 2.669 | 1.259 | False | 3.134 | 10.301 | -9.812 | -72.141 |
689 rows × 19 columns
Traffic participant properties#
There are also methods available that might help to find the relevant information in the dataset. The most straight forward option is to use pandas’ capability to access specific attributes of the datasets. The available attributes on the dataset, are available via the tasi.DLRTrajectoryDataset.attribute property.
[7]:
ds.attributes
[7]:
Index(['acceleration', 'center', 'classifications', 'dimension',
'interpolated', 'velocity', 'yaw'],
dtype='object')
We can, for instance, access the traffic participants center position.
[8]:
ds.center
[8]:
| easting | northing | ||
|---|---|---|---|
| timestamp | id | ||
| 2023-09-24 12:30:00.016482+00:00 | 1695558514712340 | 604774.496 | 5792796.320 |
| 1695558558975558 | 604740.884 | 5792779.240 | |
| 1695558561769745 | 604787.539 | 5792764.373 | |
| 1695558563216597 | 604741.853 | 5792776.267 | |
| 1695558565170472 | 604791.430 | 5792770.438 | |
| ... | ... | ... | ... |
| 2023-09-24 12:44:59.966482+00:00 | 1695559492674737 | 604789.200 | 5792769.423 |
| 1695559496120575 | 604702.210 | 5792771.596 | |
| 1695559498274800 | 604855.834 | 5792822.882 | |
| 1695559499171792 | 604740.345 | 5792785.036 | |
| 1695559499574101 | 604871.056 | 5792836.959 |
388075 rows × 2 columns
or the classification propabilities.
[9]:
ds.classifications
[9]:
| bicycle | car | motorbike | pedestrian | truck | van | ||
|---|---|---|---|---|---|---|---|
| timestamp | id | ||||||
| 2023-09-24 12:30:00.016482+00:00 | 1695558514712340 | 0.008 | 0.598 | 0.388 | 0.000 | 0.006 | 0.0 |
| 1695558558975558 | 0.000 | 0.838 | 0.163 | 0.000 | 0.000 | 0.0 | |
| 1695558561769745 | 0.000 | 0.952 | 0.037 | 0.011 | 0.000 | 0.0 | |
| 1695558563216597 | 0.000 | 0.954 | 0.026 | 0.000 | 0.000 | 0.0 | |
| 1695558565170472 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 | 0.0 | |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-09-24 12:44:59.966482+00:00 | 1695559492674737 | 0.000 | 0.979 | 0.021 | 0.000 | 0.000 | 0.0 |
| 1695559496120575 | 0.014 | 0.572 | 0.414 | 0.001 | 0.000 | 0.0 | |
| 1695559498274800 | 0.000 | 0.921 | 0.079 | 0.000 | 0.000 | 0.0 | |
| 1695559499171792 | 0.000 | 0.660 | 0.340 | 0.000 | 0.000 | 0.0 | |
| 1695559499574101 | 0.022 | 0.890 | 0.089 | 0.000 | 0.000 | 0.0 |
388075 rows × 6 columns
We extended these basic capabilities with additional methods, that, for instance, allow to get the most likely class by each traffic participant’s pose
[10]:
ds.most_likely_class(by="pose")
[10]:
timestamp id
2023-09-24 12:30:00.016482+00:00 1695558514712340 car
1695558558975558 car
1695558561769745 car
1695558563216597 car
1695558565170472 car
...
2023-09-24 12:44:59.966482+00:00 1695559492674737 car
1695559496120575 car
1695559498274800 car
1695559499171792 car
1695559499574101 car
Length: 388075, dtype: object
or by the overall trajectory (the default), i.e. all poses of a traffic participants.
[11]:
ds.most_likely_class(by="trajectory")
[11]:
id
1695558514712340 car
1695558558975558 car
1695558561769745 car
1695558563216597 car
1695558565170472 car
...
1695559492674737 car
1695559496120575 car
1695559498274800 car
1695559499171792 car
1695559499574101 car
Name: classification, Length: 750, dtype: object
This might help to filter the dataset to select only traffic participants that are classified as a car. To archieve this, we first get the most likely class per trajectory, select the rows having the value ‘car’ and pass their index (the traffic particpant’s id) into the tasi.DLRTrajectoryDataset.trajectory method.
[12]:
classification = ds.most_likely_class(by="trajectory")
ds.trajectory(classification[classification == "car"].index)
[12]:
| acceleration | center | classifications | dimension | interpolated | velocity | yaw | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| easting | magnitude | northing | easting | northing | bicycle | car | motorbike | pedestrian | truck | van | height | length | width | easting | magnitude | northing | ||||
| timestamp | id | |||||||||||||||||||
| 2023-09-24 12:30:00.016482+00:00 | 1695558514712340 | 1.068 | 1.698 | 1.320 | 604774.496 | 5792796.320 | 0.008 | 0.598 | 0.388 | 0.000 | 0.006 | 0.0 | 1.445 | 2.536 | 1.177 | False | 7.140 | 8.169 | -3.970 | -29.398 |
| 1695558558975558 | 0.014 | 0.016 | -0.008 | 604740.884 | 5792779.240 | 0.000 | 0.838 | 0.163 | 0.000 | 0.000 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.021 | 0.021 | 0.000 | 7.852 | |
| 1695558561769745 | 0.008 | 0.036 | -0.035 | 604787.539 | 5792764.373 | 0.000 | 0.952 | 0.037 | 0.011 | 0.000 | 0.0 | 1.311 | 3.445 | 1.409 | False | -0.008 | 0.042 | 0.041 | 107.830 | |
| 1695558563216597 | -0.041 | 0.044 | -0.014 | 604741.853 | 5792776.267 | 0.000 | 0.954 | 0.026 | 0.000 | 0.000 | 0.0 | 1.468 | 3.323 | 1.293 | False | -0.030 | 0.044 | 0.032 | 9.183 | |
| 1695558565170472 | -0.002 | 0.004 | -0.004 | 604791.430 | 5792770.438 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 | 0.0 | 1.556 | 3.407 | 1.775 | False | -0.000 | 0.013 | 0.013 | 116.146 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-09-24 12:44:59.966482+00:00 | 1695559492674737 | 0.612 | 2.202 | -2.115 | 604789.200 | 5792769.423 | 0.000 | 0.979 | 0.021 | 0.000 | 0.000 | 0.0 | 1.318 | 3.642 | 1.634 | False | -0.813 | 2.602 | 2.471 | 108.191 |
| 1695559496120575 | -0.850 | 0.857 | 0.111 | 604702.210 | 5792771.596 | 0.014 | 0.572 | 0.414 | 0.001 | 0.000 | 0.0 | 1.304 | 2.280 | 0.931 | False | 8.734 | 8.745 | 0.456 | 2.955 | |
| 1695559498274800 | -0.009 | 0.253 | 0.252 | 604855.834 | 5792822.882 | 0.000 | 0.921 | 0.079 | 0.000 | 0.000 | 0.0 | 1.385 | 3.026 | 1.385 | False | -13.271 | 14.496 | -5.832 | -156.208 | |
| 1695559499171792 | 1.309 | 1.314 | 0.118 | 604740.345 | 5792785.036 | 0.000 | 0.660 | 0.340 | 0.000 | 0.000 | 0.0 | 1.269 | 2.907 | 1.451 | False | 5.195 | 5.274 | 0.908 | 9.847 | |
| 1695559499574101 | -0.422 | 0.423 | -0.030 | 604871.056 | 5792836.959 | 0.022 | 0.890 | 0.089 | 0.000 | 0.000 | 0.0 | 1.389 | 3.028 | 1.593 | False | -15.391 | 16.423 | -5.728 | -159.568 | |
344669 rows × 19 columns
You can achieve the same result by directly calling
[13]:
ds.cars
[13]:
| acceleration | center | classifications | dimension | interpolated | velocity | yaw | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| easting | magnitude | northing | easting | northing | bicycle | car | motorbike | pedestrian | truck | van | height | length | width | easting | magnitude | northing | ||||
| timestamp | id | |||||||||||||||||||
| 2023-09-24 12:30:00.016482+00:00 | 1695558514712340 | 1.068 | 1.698 | 1.320 | 604774.496 | 5792796.320 | 0.008 | 0.598 | 0.388 | 0.000 | 0.006 | 0.0 | 1.445 | 2.536 | 1.177 | False | 7.140 | 8.169 | -3.970 | -29.398 |
| 1695558558975558 | 0.014 | 0.016 | -0.008 | 604740.884 | 5792779.240 | 0.000 | 0.838 | 0.163 | 0.000 | 0.000 | 0.0 | 1.261 | 2.669 | 1.259 | False | 0.021 | 0.021 | 0.000 | 7.852 | |
| 1695558561769745 | 0.008 | 0.036 | -0.035 | 604787.539 | 5792764.373 | 0.000 | 0.952 | 0.037 | 0.011 | 0.000 | 0.0 | 1.311 | 3.445 | 1.409 | False | -0.008 | 0.042 | 0.041 | 107.830 | |
| 1695558563216597 | -0.041 | 0.044 | -0.014 | 604741.853 | 5792776.267 | 0.000 | 0.954 | 0.026 | 0.000 | 0.000 | 0.0 | 1.468 | 3.323 | 1.293 | False | -0.030 | 0.044 | 0.032 | 9.183 | |
| 1695558565170472 | -0.002 | 0.004 | -0.004 | 604791.430 | 5792770.438 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 | 0.0 | 1.556 | 3.407 | 1.775 | False | -0.000 | 0.013 | 0.013 | 116.146 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-09-24 12:44:59.966482+00:00 | 1695559492674737 | 0.612 | 2.202 | -2.115 | 604789.200 | 5792769.423 | 0.000 | 0.979 | 0.021 | 0.000 | 0.000 | 0.0 | 1.318 | 3.642 | 1.634 | False | -0.813 | 2.602 | 2.471 | 108.191 |
| 1695559496120575 | -0.850 | 0.857 | 0.111 | 604702.210 | 5792771.596 | 0.014 | 0.572 | 0.414 | 0.001 | 0.000 | 0.0 | 1.304 | 2.280 | 0.931 | False | 8.734 | 8.745 | 0.456 | 2.955 | |
| 1695559498274800 | -0.009 | 0.253 | 0.252 | 604855.834 | 5792822.882 | 0.000 | 0.921 | 0.079 | 0.000 | 0.000 | 0.0 | 1.385 | 3.026 | 1.385 | False | -13.271 | 14.496 | -5.832 | -156.208 | |
| 1695559499171792 | 1.309 | 1.314 | 0.118 | 604740.345 | 5792785.036 | 0.000 | 0.660 | 0.340 | 0.000 | 0.000 | 0.0 | 1.269 | 2.907 | 1.451 | False | 5.195 | 5.274 | 0.908 | 9.847 | |
| 1695559499574101 | -0.422 | 0.423 | -0.030 | 604871.056 | 5792836.959 | 0.022 | 0.890 | 0.089 | 0.000 | 0.000 | 0.0 | 1.389 | 3.028 | 1.593 | False | -15.391 | 16.423 | -5.728 | -159.568 | |
344669 rows × 19 columns
This works similarly for all object classes.
[14]:
ds.trucks
[14]:
| acceleration | center | classifications | dimension | interpolated | velocity | yaw | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| easting | magnitude | northing | easting | northing | bicycle | car | motorbike | pedestrian | truck | van | height | length | width | easting | magnitude | northing | ||||
| timestamp | id | |||||||||||||||||||
| 2023-09-24 12:30:00.016482+00:00 | 1695558573520980 | 0.492 | 1.190 | -1.084 | 604755.520 | 5792806.976 | 0.0 | 0.002 | 0.011 | 0.0 | 0.548 | 0.433 | 3.121 | 4.165 | 1.852 | False | 2.015 | 5.623 | -5.249 | -69.038 |
| 2023-09-24 12:30:00.066482+00:00 | 1695558573520980 | 0.492 | 1.189 | -1.082 | 604755.628 | 5792806.699 | 0.0 | 0.002 | 0.011 | 0.0 | 0.548 | 0.433 | 3.121 | 4.165 | 1.852 | False | 2.048 | 5.699 | -5.319 | -68.982 |
| 2023-09-24 12:30:00.116482+00:00 | 1695558573520980 | 0.492 | 1.187 | -1.080 | 604755.737 | 5792806.418 | 0.0 | 0.002 | 0.011 | 0.0 | 0.548 | 0.433 | 3.121 | 4.165 | 1.852 | False | 2.080 | 5.775 | -5.388 | -68.927 |
| 2023-09-24 12:30:00.166482+00:00 | 1695558573520980 | 0.491 | 1.184 | -1.077 | 604755.847 | 5792806.134 | 0.0 | 0.002 | 0.011 | 0.0 | 0.548 | 0.433 | 3.121 | 4.165 | 1.852 | False | 2.112 | 5.851 | -5.457 | -68.874 |
| 2023-09-24 12:30:00.216482+00:00 | 1695558573520980 | 0.490 | 1.180 | -1.073 | 604755.960 | 5792805.846 | 0.0 | 0.002 | 0.011 | 0.0 | 0.548 | 0.433 | 3.121 | 4.165 | 1.852 | False | 2.145 | 5.927 | -5.525 | -68.822 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-09-24 12:44:59.766482+00:00 | 1695559485974970 | 0.064 | 0.077 | 0.042 | 604811.791 | 5792808.842 | 0.0 | 0.000 | 0.000 | 0.0 | 1.000 | 0.000 | 3.037 | 13.167 | 3.224 | False | 0.031 | 0.039 | 0.023 | -153.082 |
| 2023-09-24 12:44:59.816482+00:00 | 1695559485974970 | 0.059 | 0.071 | 0.040 | 604811.792 | 5792808.843 | 0.0 | 0.000 | 0.000 | 0.0 | 1.000 | 0.000 | 3.037 | 13.167 | 3.224 | False | 0.030 | 0.038 | 0.023 | -153.082 |
| 2023-09-24 12:44:59.866482+00:00 | 1695559485974970 | 0.054 | 0.066 | 0.038 | 604811.794 | 5792808.843 | 0.0 | 0.000 | 0.000 | 0.0 | 1.000 | 0.000 | 3.037 | 13.167 | 3.224 | False | 0.028 | 0.037 | 0.023 | -153.082 |
| 2023-09-24 12:44:59.916482+00:00 | 1695559485974970 | 0.049 | 0.061 | 0.036 | 604811.795 | 5792808.843 | 0.0 | 0.000 | 0.000 | 0.0 | 1.000 | 0.000 | 3.037 | 13.167 | 3.224 | False | 0.026 | 0.035 | 0.023 | -153.082 |
| 2023-09-24 12:44:59.966482+00:00 | 1695559485974970 | 0.045 | 0.057 | 0.035 | 604811.797 | 5792808.844 | 0.0 | 0.000 | 0.000 | 0.0 | 1.000 | 0.000 | 3.037 | 13.167 | 3.224 | False | 0.024 | 0.034 | 0.023 | -153.082 |
7076 rows × 19 columns
Custom filter or transformator#
You can also build your own filter or transformator that may apply to the trajectory or pose level. For this purpose, the TrajectoryDataset.apply method can be used.
For example, let’s assume that you want to analyse the length of the different trajectories within a dataset. This may be useful for finding anomalies. In the following, we will count the number of measurements per traffic participant.
[15]:
import pandas as pd
tj_length = ds.apply(len, by="trajectory")
# create bins of width 100 measurements and count traffic participants within bins
ds_binned = pd.cut(tj_length, range(0, tj_length.max(), 100))
counts = ds_binned.value_counts().sort_index()
ax = counts.plot(kind="bar")
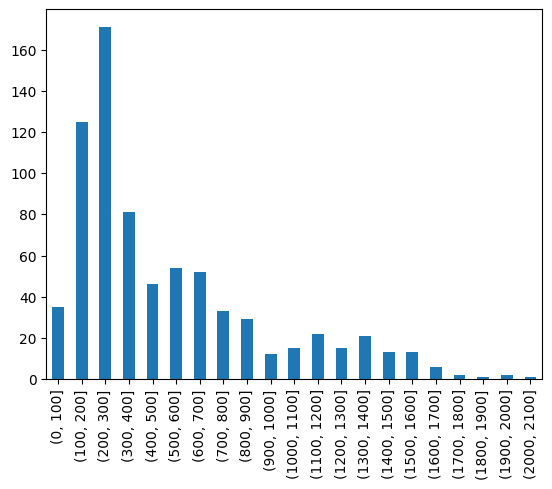
If you are instead interested in the length of each trajectory in meter, we can utilize shapely. To achieve this, we convert the tasi.TrajectoryDataset to a tasi.GeoTrajectoryDataset and gain access to the shapely feature set. This enables us to use the length attribute which is the length of the geometry.
[16]:
import numpy as np
gds = ds.as_geopandas("center")
gds.set_geometry("center", inplace=True)
tj_length = gds.length
# create bins of width 100 measurements and count traffic participants within bins
ds_binned = pd.cut(tj_length, range(0, np.int32(np.round(tj_length.max())), 10))
counts = ds_binned.value_counts().sort_index()
ax = counts.plot(kind="bar")
